
Practical Considerations for Developers Using Kafka
This is the blog post form of a presentation I have given on this topic.
Key takeaways
- Like most distributed systems, Kafka should not be treated like a closed box, but rather - we need to understand how it works in order to leverage it in the best way possible.
- Kafka offers many configuration options which allows us to optimise for a large set of functional guarantees, traffic types and non-functional requirements.
- Any choices or trade-offs we make should be driven by the use case we have.
Apache Kafka is an amazing piece of technology designed to be highly performant, durable and resilient. It is part of a generation of Big Data distributed systems which can add a lot of value to a business use case, if used correctly. However, there is an inherent complexity with how Kafka (or any other large-scale distributed system) works, and this complexity cannot be completely hidden from developers. While Kafka has pretty sensible defaults, we still have to understand its inner workings - we can’t treat it as a closed system. We have to lift the hood, learn about how it works, and then figure out how to leverage it to achieve the business purpose we are interested in.
We have to lift the hood, learn about how it works
This post is not about this. There will be some of that, but it will not be the focus of the post. Existing knowledge about how Kafka works is recommended. There are plenty of high quality resources out there that can help developers with learning about Kafka (e.g. documentation; Confluent’s blog; books).
and then figure out how to leverage it to achieve a business purpose
This post is about this. We want to compare and contrast how different use-cases have conflicting requirements, and how this influences the way we work with Kafka. All of this still leaves a lot to cover, so here’s the scope of this post:
- We will focus on the different guarantees Kafka offers, like event ordering by partition, and the different possible message delivery semantics.
- We will discuss several different possible workload types and non-functional requirements.
- We will look at some configuration options of the Kafka clients (producer / consumer), and the broker (topic configuration).
- We will focus on the primitive Kafka clients - consumer / producer, not, Kafka Streams, ksqlDB, etc.
- We will not focus on the operational aspects of running a Kafka cluster.
- We will not be deep-diving on recovery patterns.
Ready? Let’s get stuck in!
To frame the discussion, we will look at 3 different requirement groups we might have. We will combine some of them to formulate a few use cases, and we will explore how we can align Kafka to support these use cases. The 3 requirement groups are:
- Functional guarantees
- Traffic type
- Non-functional requirements
Here they are with concrete requirements in each group:
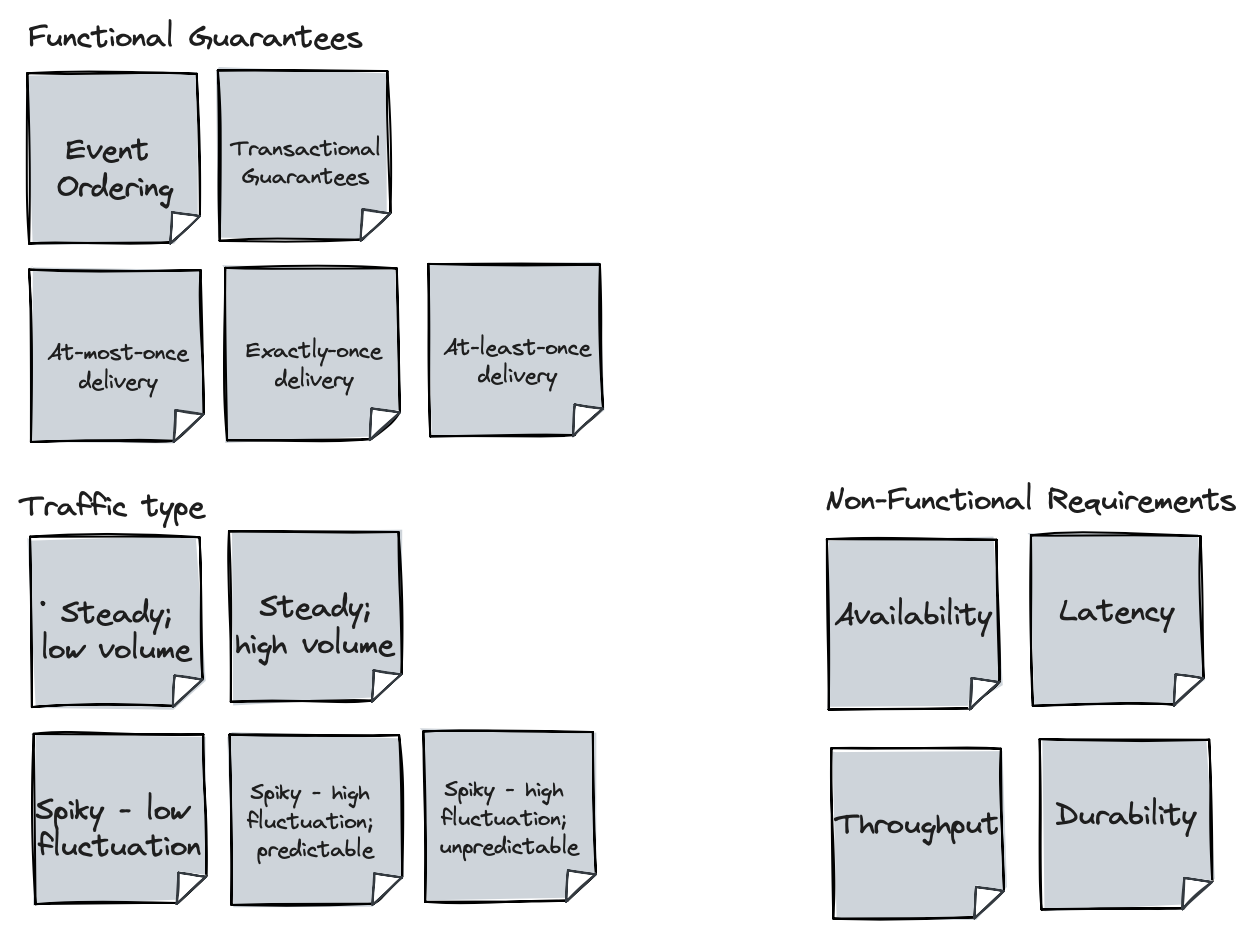
The different traffic types are vague and can mean different things to different people in different contexts. That’s okay. We can’t conceivably enumerate all patterns, but what we have there can serve to drive the discussion. We will further clarify and make these traffic types concrete as we describe various use cases.
We should clarify what we mean by the non-functional requirements:
- Availability - the ability of the system to function or minimise downtime in the face of failures.
- Latency - the time it takes to move an event from a producer through the broker and to the consumer.
- Throughput - the amount of data moved through the system in a given amount of time.
- Durability - the assurance that events that got into the system would not be lost or unprocessed.
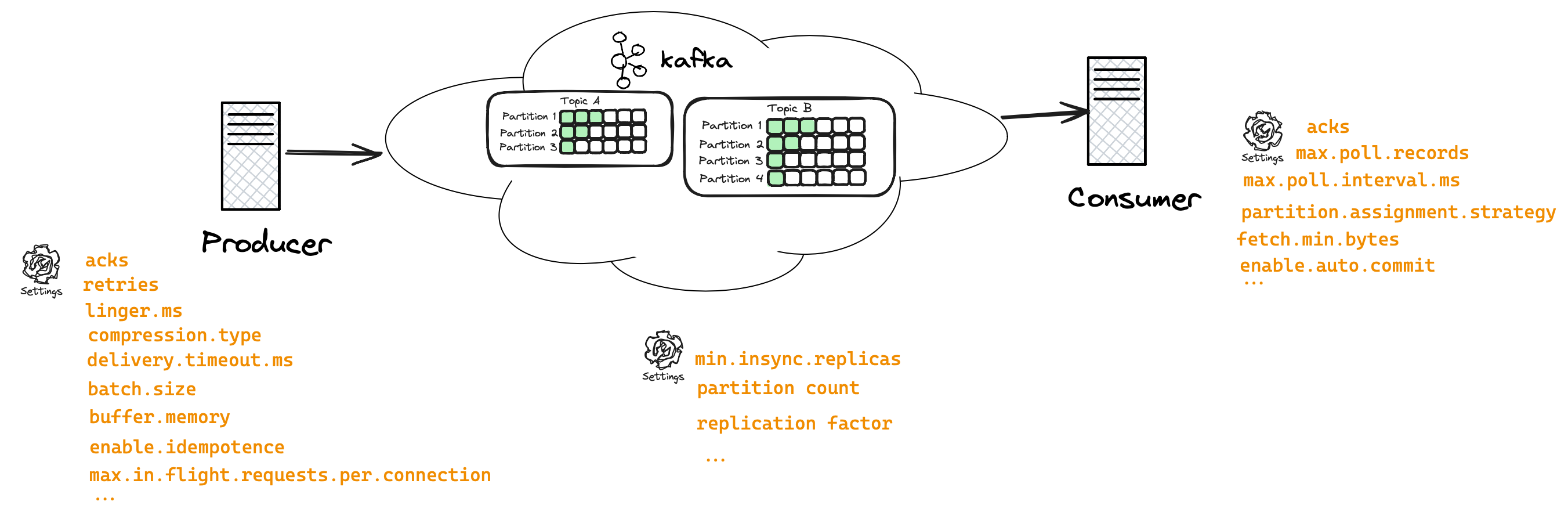
Let’s also remind ourselves what Kafka looks like from a high level:
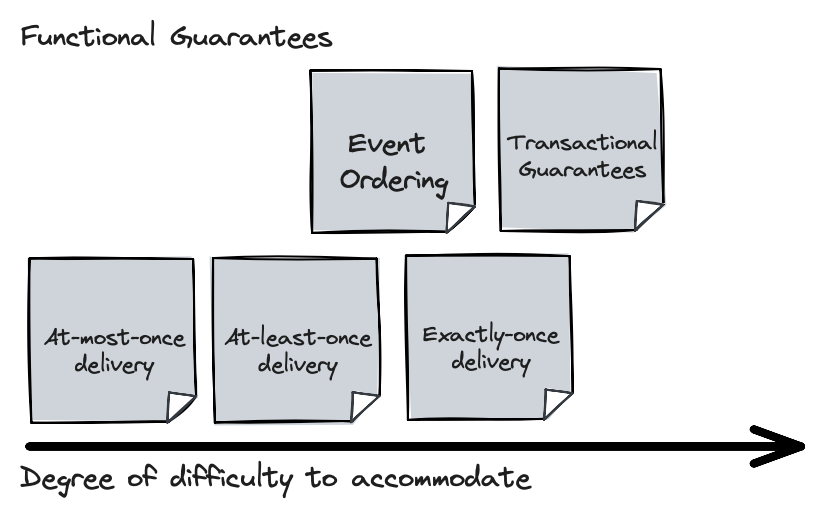
Before we go through some example use cases, let’s order some of the requirements based on the expected difficulty to accommodate them. The non-functional requirements are hard to quantify like that, but we could put the functional guarantees on a spectrum of difficulty like this:
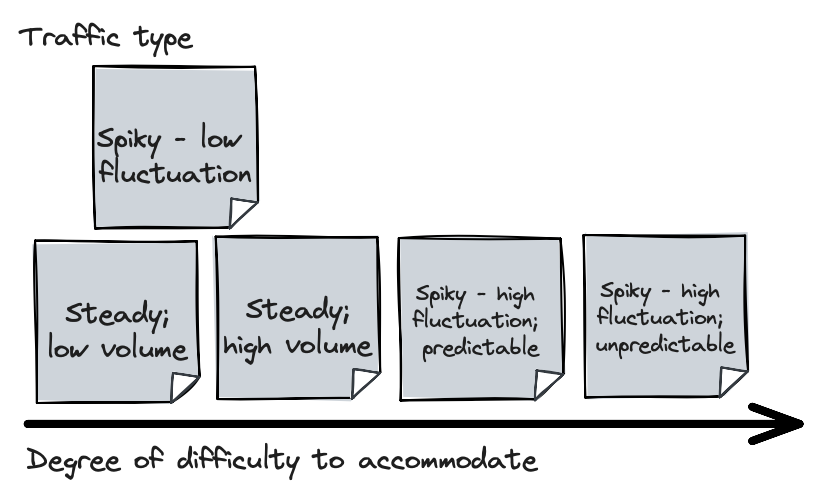
We can do the same for the various traffic types:

Simplest use case
Let’s first look at what the easiest use case could be: at-most-once delivery guarantee, no event ordering required, and a steady low traffic type. It’s quite hard to imagine a real world use case for this, but it serves as a good starting point.
The use case leads us naturally to choose latency or availability as a non-functional requirement to optimise for. Let’s prioritise latency, but also optimise for availability where we can.
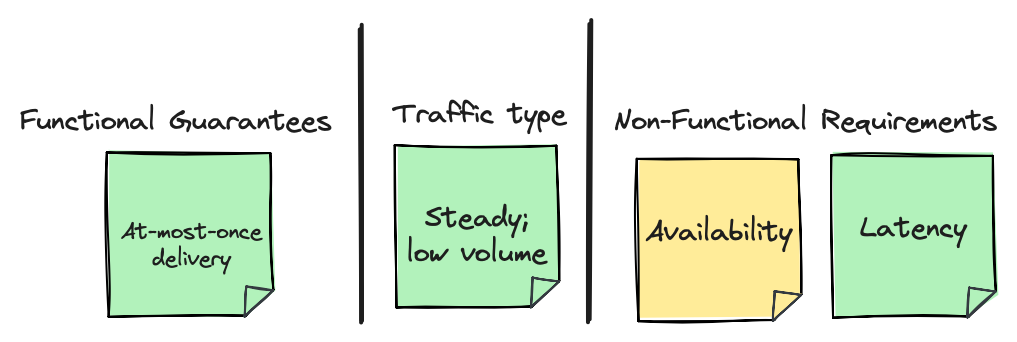
The good news is that we barely have to tune anything - Kafka’s defaults will handle a use case like this for us.
Topic configurations
Confluent has a guide on choosing the partition numbers required for a topic. The formula to choose the minimum number of partitions is max(t/p, t/c) partitions where:
t= desired throughput in MBs per secondp= producer throughput on a single partition in MBs per second (keep in mind this is flexible depending on how your producer is configured, but usually operates in the 10s of MB per second)c= consumer throughput (this is application dependent)
Based on our requirements, there’s no need to go overboard with partitions. We will be fine with 1! If we make up some numbers to quantify what “steady; low volume” means, let’s say we have max throughput of 1MB/s, producer throughput assumed 30 MB/s, and consumer throughput assumed 20 MB/s. If we plug these numbers into the formula above, we get max(1/30, 1/20)=0.05 which is a single partition.
There is also a tool called Event Sizer which you can use to forecast the number of partitions you might need. If we use that, and we tell it that we will have 1 event every second, with a growth multiplier of 2, and a 10ms consumer processing time, we still get a single partition back.
All that being said, if I had to implement this in production, I would still go for 2 or 3 partitions. The reason is that, if you have a single partition, then you can only have a single consumer in a consumer group consuming from it. However, having a singleton instance of a service isn’t ideal, especially if you’re running on top of an orchestrated cloud environment like K8s. You could have multiple consumers in a group and have some of them be idle, effectively acting like a passive backup of the active consumer. If you were to do that, though, it makes sense to give these idle consumers something to do, and giving them a partition comes at virtually no cost - so why not do it?
Producer configurations
Here are the main producer side configurations to consider:
linger.ms- Producers batch messages, and
linger.msis what’s used to control the time given to collect batches. The default of 0 means we have minimum latency - the moment something’s available, be it a batch of multiple messages or a single message, the producer will send it to the broker.
- Producers batch messages, and
acks- The number of acknowledgments the producer requires the leader to have received before considering a request complete.
- Defaults to 1. Since our requirement is “at-most-once” delivery, we can set it to 0. This will further reduce our latency - the producer will not wait at all for a confirmation from the broker.
compression.type- Specify the final compression type for a given topic.
- Default:
none. - Compression is a trade-off between the CPU effort to do the compression, and the reduced network throughput. This is probably something to experiment with - there is a chance a good compression codec might reduce your latency, but it also might increase it.
retries- Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error.
- Default value: 2147483647 (INT_MAX)
- This is a large value, but it doesn’t mean the producer will do all of these retries. Retries are only done within the bound set by
delivery.timeout.ms, which defaults to 2 mins. - If we truly want to go hardcore on the at-most-once mentality, then we could override
retriesto 0 to avoid any retries.
Consumer configurations
fetch.min.bytes- The minimum amount of data the server should return for a consumer fetch request.
- Default: 1.
- If optimising for latency, we should leave the default - it means that as soon as a single byte of data is available, a fetch request will be answered.
Since the use case requires at-most-once delivery, we might want to prevent events being consumed twice at all. If we wanted to do that, we could publish our consumer offsets the moment we read messages from the broker, before the consumer has processed them. This means that we might lose some events - if the consumer process fails during processing, its position in the Kafka log has already been updated, so it will not try to reprocess the events again.
Honourable mentions:
max.poll.interval.ms- This places an upper bound on the amount of time that the consumer can be idle before fetching more records.
- Default: 300000 (5 minutes)
- If consumers need a looong time to process an event, then you might consider setting this higher, but I doubt this is a requirement often in the real world.
max.poll.records- The maximum number of records returned in a single call to poll().
- Default: 500
- Related to
max.poll.interval.ms- if we have too many records coming in, and each of them requiring a long time to process, the consumer can time out. This can be used to reduce the number of records returned in a single call topoll().
Let’s bump up the volume!
While the previous use case is hard to imagine in the real world, a more realistic one might be to have a traffic type of “Steady; high volume”, and keeping the rest of the requirements the same. Perhaps it is stream of sensory data from a fleet of IoT devices.
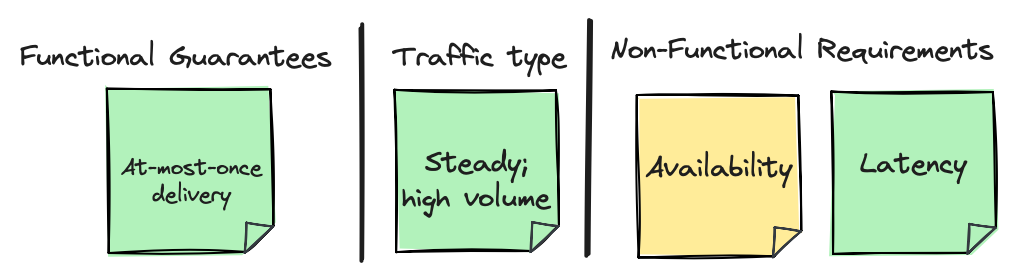
Topic configurations
We have to apply the formula for partitions, depending on what “high volume” means. It’s a murky definition of load - what high volume means will be different in different environments. For the sake of the argument, let’s say it means desired throughput of 200 MB/s, and let’s keep the assumed producer and consumer throughputs from the previous example - 30MB/s and 20MB/s respectively. Plugging these figures into the formula gives us: max(200/30, 200/20)=10 partitions for the topic.
Keep in mind - this is the minimum partitions we should provision. Since partitions are the unit of parallelism in Kafka, if we want to scale out the consumer processing further, we have to increase the number of partitions.
Another factor to consider is the expected future growth in volume - the Event Sizer tool has a dedicated property for this - the growth multiplier. It is generally encouraged to forecast what our expected usage might be in a couple of years’ time, and size our partitions based on that, rather than our current workloads. This is particularly true for use cases which require ordering - since partition ordering is based on keys, changing the number of partitions means events with the same key might end up on different partitions, and hence be consumed out of order by different consumers. This is not an aspect we have to worry about for this use case, though.
Note - there are dangers of over-provisioning the partitions, including a potentially increased E2E latency, but that doesn’t mean there isn’t a balance to be struck.
Producer configurations
What we covered in the previous use case still applies.
Consumer configurations
What we covered in the previous use case still applies. To further improve latency in the face of increased volume, we could look at another consumer property:
partition.assignment.strategy- …supported partition assignment strategies that the client will use to distribute partition ownership amongst consumer instances when group management is used.
- Default:
class org.apache.kafka.clients.consumer.RangeAssignor,class org.apache.kafka.clients.consumer.CooperativeStickyAssignor - This is important, because as partition counts increase, consumer rebalances start to become more expensive. This means that there will be more and longer periods of time where consumption will be halted. Confluent have an excellent blog post explaining the details.
- Change to: org.apache.kafka.clients.consumer.CooperativeStickyAssignor
Let’s optimise for throughput, and increase the delivery guarantee
What would happen if our requirements changed, so we had to prioritise throughput, and we also wanted at-least-once delivery? The at-least-once delivery guarantee also means we should be optimising for durability. It is difficult to optimise both throughput and durability, so let’s prioritise throughput first.
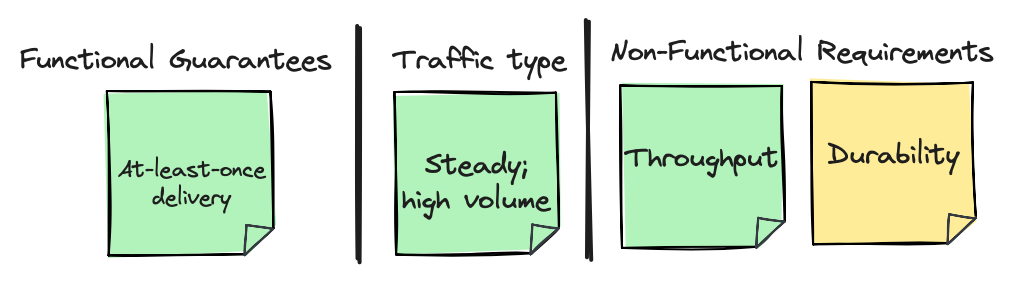
Topic configurations
We probably don’t need to change much here, but a higher partition count is generally associated with increased throughput - partitions are Kafka’s unit of parallelism. We might choose to increase the number of partitions, however, as mentioned before, there could be some downsides if we go overboard. Increased partition count would also likely translate in increased consumer count for most efficient processing. This will also increase the costs of running all consumer instances. Whether we increase the partitions or not will depend on the specific context.
Producer configurations
In most ways, how we want to configure the producer for throughput is the opposite of what we wanted for latency.
batch.size- The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition.[…] This configuration controls the default batch size in bytes.
- Default value: 16384
- You can increase this to help accommodate more bytes in each batch. This will help increase your throughput.
linger.ms- It makes sense to increase this from the default of 0. Confluent suggests a value between 10-100. This warrants some experimentation. If the traffic volume is really high, then this could be a lower number, since it wouldn’t take as much to fill up the batch.
acks- We should probably leave the default value of 1 here. This will go a long way to support the at-least-once guarantee, while also not wasting too much time while the producer waits for acknowledgements. If we have a very strong durability guarantee, we could use
all.
- We should probably leave the default value of 1 here. This will go a long way to support the at-least-once guarantee, while also not wasting too much time while the producer waits for acknowledgements. If we have a very strong durability guarantee, we could use
compression.type- Since we’re optimising for throughput, enabling compression makes sense. Confluent suggest using the
lz4compression type.
- Since we’re optimising for throughput, enabling compression makes sense. Confluent suggest using the
buffer.memory- The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are sent faster than they can be delivered to the server the producer will block for
max.block.msafter which it will throw an exception. - Default value: 33554432
- If we have many partitions, and we have increased the
batch.sizesubstantially, we might have to consider increasingbuffer.memory, in accordance with the linger time, batch size and partition count.
- The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are sent faster than they can be delivered to the server the producer will block for
Partitioning edge case
If you partition your events (because of ordering guarantees or some other reason, we’ll look into that in detail in the next section), and throughput is important to you, then you have to be careful to avoid hot partitions. Hot partitions occur when some particular keys see a lot more events than others. This would mean that these partitions would see a disproportionately large amount of traffic compared to others, thus reducing parallelism. For example, if our project has to process payments in different currencies, and we key payment events based on the currency, there is a potential for a partition to become hot - if we primarily deal in USD payments, then all of these would go to the same partition. So we will be constrained by the processing ability of the specific consumer assigned to this partition.
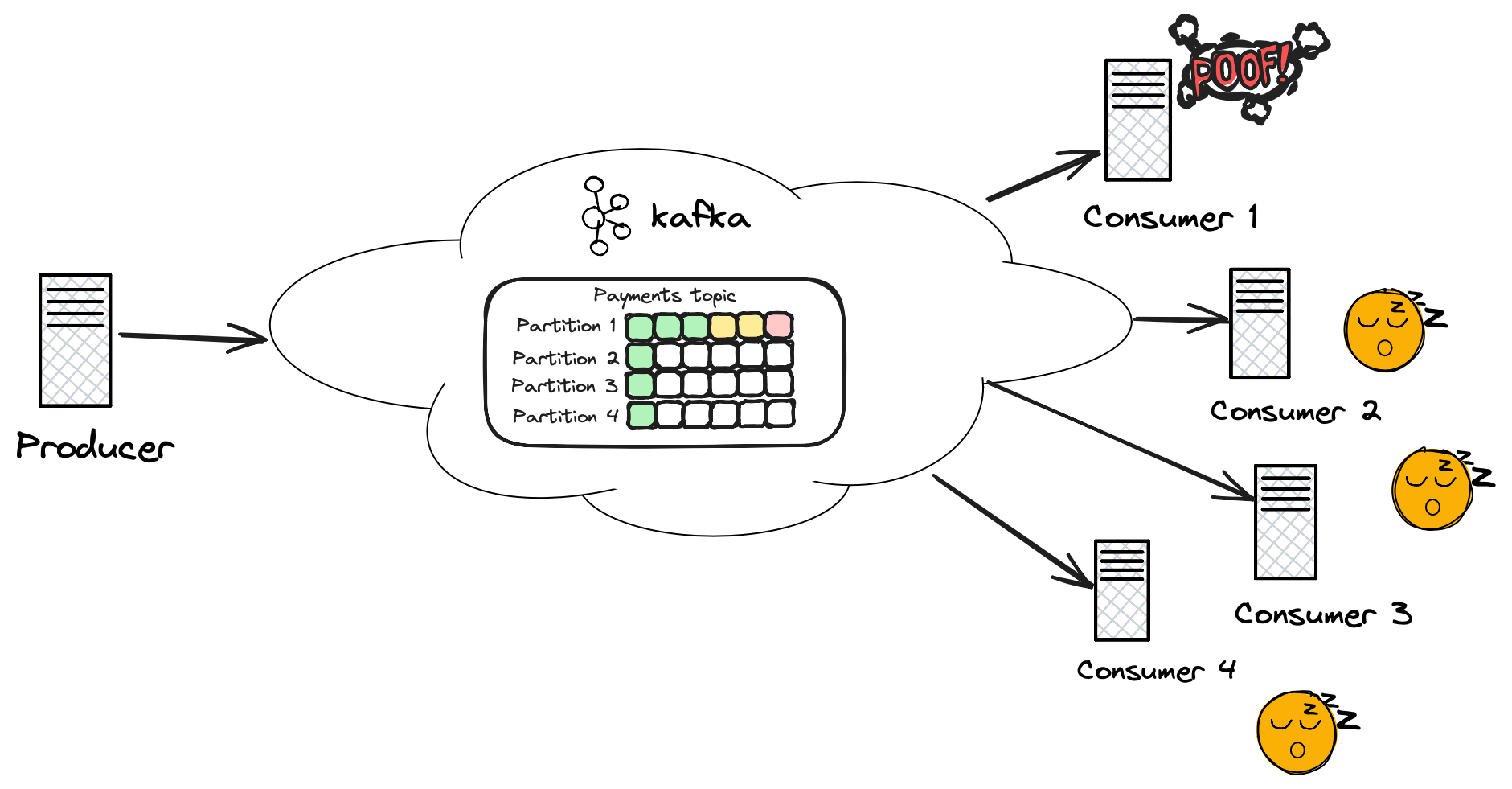 

There isn’t a single solution that will work to avoid hot partitions. It all depends on the business use case and what our options are. For example, instead of keying by only currency, we could use a composite key using customer account identifier and currency. This should distribute the events a lot more evenly across partitions, and could still align with our ordering guarantees if we care about ordering based on a customer level, not global ordering per currency. It all depends on the project requirements and use case.
Note - Kafka allows us to create our own partitioning logic by extending the Partitioner interface.
Consumer configurations
Again, it’s likely the changes we’re making to the consumer configuration will trade-off latency for throughput.
fetch.min.bytes- We should increase this from its default value of 1. By how much depends on our context, the volume of data, etc. Some experimentation and measurements are likely needed.
Since we have at-least-once delivery guarantees now, consumers should commit their offsets only after they have processed their events. This will help resilience in the face of consumer failure - if a consumer process fails during processing, once it’s able to read from the partition again, it will again consume the same events and retry their processing.
Given the above, consumer idempotency becomes an important concern - we need to ensure that processing the same event twice (or more!) does not result in data integrity issues!
What about very strong consistency?
Let’s say we have to tackle a different scenario - we need to guarantee ordering of events, and also ensure each event appears on the log exactly once, while maintaining strong durability.

Topic configurations
- Replication factor
- A replication factor of 3 is generally a good choice. One could go higher, but this increases the broker overhead of maintaining all replicas.
min.insync.replicas- When a producer sets acks to “all” (or “-1”), this configuration specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful.
- Default value: 1
- Confluent have an excellent explanation about the subtleties of how
acksworks and interacts withmin.insync.replicas. - If the replication factor is 3, and we require strong durability, then we could set
min.insync.replicasto 2 to ensure that always a majority of replicas receive the write.
Producer configurations
acks- We should set this to
allwhich gives us the highest durability guarantees.
- We should set this to
delivery.timeout.ms- An upper bound on the time to report success or failure after a call to send() returns. This limits the total time that a record will be delayed prior to sending, the time to await acknowledgement from the broker (if expected), and the time allowed for retryable send failures.
- Default value: 120000 (2 minutes)
- We could increase this, in order to give our producers more time to retry and deliver a message, which will help with durability.
enable.idempotence- When set to ‘true’, the producer will ensure that exactly one copy of each message is written in the stream. If ‘false’, producer retries due to broker failures, etc., may write duplicates of the retried message in the stream.
- Note that enabling idempotence requires
max.in.flight.requests.per.connectionto be less than or equal to 5 (with message ordering preserved for any allowable value),retriesto be greater than 0, andacksmust be ‘all’. - Idempotence is enabled by default if no conflicting configurations are set. If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled.
- Note that enabling idempotence requires
- Default value:
true - We should leave this to the default value.
- When set to ‘true’, the producer will ensure that exactly one copy of each message is written in the stream. If ‘false’, producer retries due to broker failures, etc., may write duplicates of the retried message in the stream.
max.in.flight.requests.per.connection- The maximum number of unacknowledged requests the client will send on a single connection before blocking.
- Default value: 5
- If we don’t want to enable idempotency on the producer side, but we want to ensure event ordering, then we should set
max.in.flight.requests.per.connectionto 1. This will preserve message ordering in the face of producer retries. If we allow for multiple connections in flight, the producer might sendRequest1that fails, andRequest2that succeeds. When the producer retriesRequest1, it will appear in the log afterRequest2.
Consumer configurations
enable.auto.commit- If true the consumer’s offset will be periodically committed in the background. “Periodically” means the value of
auto.commit.interval.mswhich defaults to 5 seconds. - Default value:
true- Note - if you use a Spring Kafka consumer client, then the default for you is actually
false, as described by the Spring Kafka documentation.
- Note - if you use a Spring Kafka consumer client, then the default for you is actually
- We talked about ensuring that offsets are committed only after the consumer has processed the messages, not before. If we wanted to be very explicit that this is the only time we want this to happen, then we should set
enable.auto.committofalseand ensure we commit the offsets explicitly.
- If true the consumer’s offset will be periodically committed in the background. “Periodically” means the value of
Spiky loads
When it comes to the spiky traffic types with high fluctuation, most of what we discussed before will stand - we would still have some functional guarantees we would need to satisfy, along with some non-functional guarantees we care about.
The reason the predictable traffic type is deemed easier is because we have the power to control the environment better. If, for example, we know that at 6pm every day something happens and a flood of events goes through the system for 30 minutes, we could conceivably:
- Provision enough partitions to handle the load comfortably
- Provision a lower number of consumer for BAU operations, so each consumer processes events from multiple partitions during low volume traffic
- Schedule a scaling up operation before the expected increase in traffic occurs
- Schedule a scaling down operation after traffic resumes to normal
This wouldn’t be so easy for the unpredictable traffic type. It would be impossible to know in advance whether to scale the consumer up or down. So we would have to make a choice - always have the full number of consumers running at all times, even though we won’t need all that processing power for some of the time, or have autoscaling consumer logic.
There are too many variables and subtleties to discuss with the autoscaling approach. An excellent resource I have found on the topic is an article by Netflix on migrating some of their workloads to Kafka.
What about …?
What about transactionality? What about error handling patterns? What about <use-case not covered>?
There are many more topics we could cover. But we won’t. Because this post (presentation) is already too long. It is impossible to enumerate all possible use cases or scenarios. The goal of this post isn’t to give specific answers to any questions. It’s to bring up some questions you should be asking yourself about the trade-offs you’re making with the way you’re using Kafka.
I find that the visual framework of capturing the different possible requirements and grouping them by the use case helps a lot with thinking through how to solve a particular problem. I think of Kafka like a huge dashboard with dials and buttons - the various combinations of settings result in different outcomes, and we shouldn’t randomly turn this dial or press that button. I hope that this post has helped make it clear that if we want to be successful when working with Kafka, we can’t allow ourselves to treat it like a closed system, and we have to be deliberate about how we approach the various trade-offs.
Good luck!
Resources
- Apache Kafka Docs
- Recommendations for Developers using Confluent Cloud
- Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
- Top 5 Things Every Apache Kafka Developer Should Know
- 5 Common Pitfalls When Using Apache Kafka
- How to Choose the Number of Topics/Partitions in a Kafka Cluster?